Reasons to implement a data classification program:
- Increase awareness about data sensitivity and data security
- Reduce risks of accidental data leakage and data storage costs
- Minimize data ownership and management costs
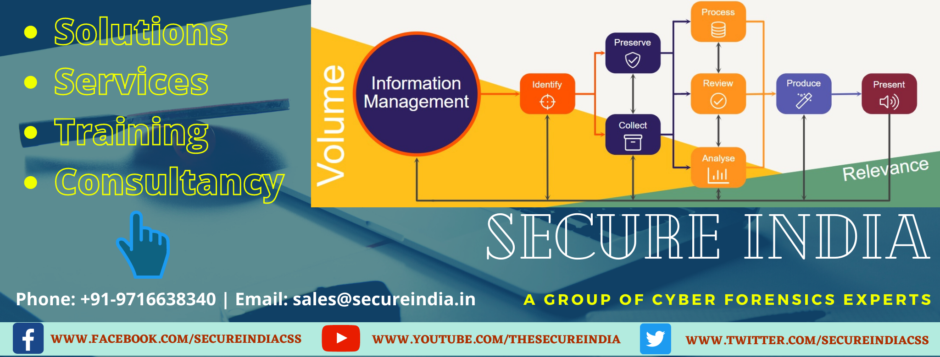
In business parlance, data classification is the process of categorizing all data present in an enterprise into groups, based on certain shared characteristics “like sensitivity, value to the organization”. The objective is to find and manage sensitive data efficiently and prevent data breaches. Data classification is one of the crucial steps of a data protection program in any enterprise. Data Classification allows recognition and labelling of sensitive data from the multitude of data present across an enterprise infrastructure. Once sensitive data is identified, organizations can implement applicable processes and controls in place to manage & protect data on an ongoing basis and reduce risk of exposure & breach.

My Personal Information-My Safety-My Responsibility?
The responsibility for protecting Personal information (PI) is not solely attributed to organizations, responsibility may be shared with the individual owners of the data. Companies may or may not be legally liable for the PI they hold.
In most cases, organizations are responsible for any leakage or illegal distribution of data. Protecting the data is their responsibility. Organizations must implement the best solution or service to protect end-users data which they hold. Securing Personal Information (PI) is divided into both sides, the user and the organization. User has to be informed where he had submitted the data and ask to organization to remove it if goal is achieved.
What is Data Classification
Data classification defines and classifies data according to its type, sensitivity, and perceived value and loss to the organization, if edited, compromised, or deleted, either knowingly or unknowingly. It helps an organization understand the value of its data, determine whether the data is at risk, and implement controls to mitigate risks.
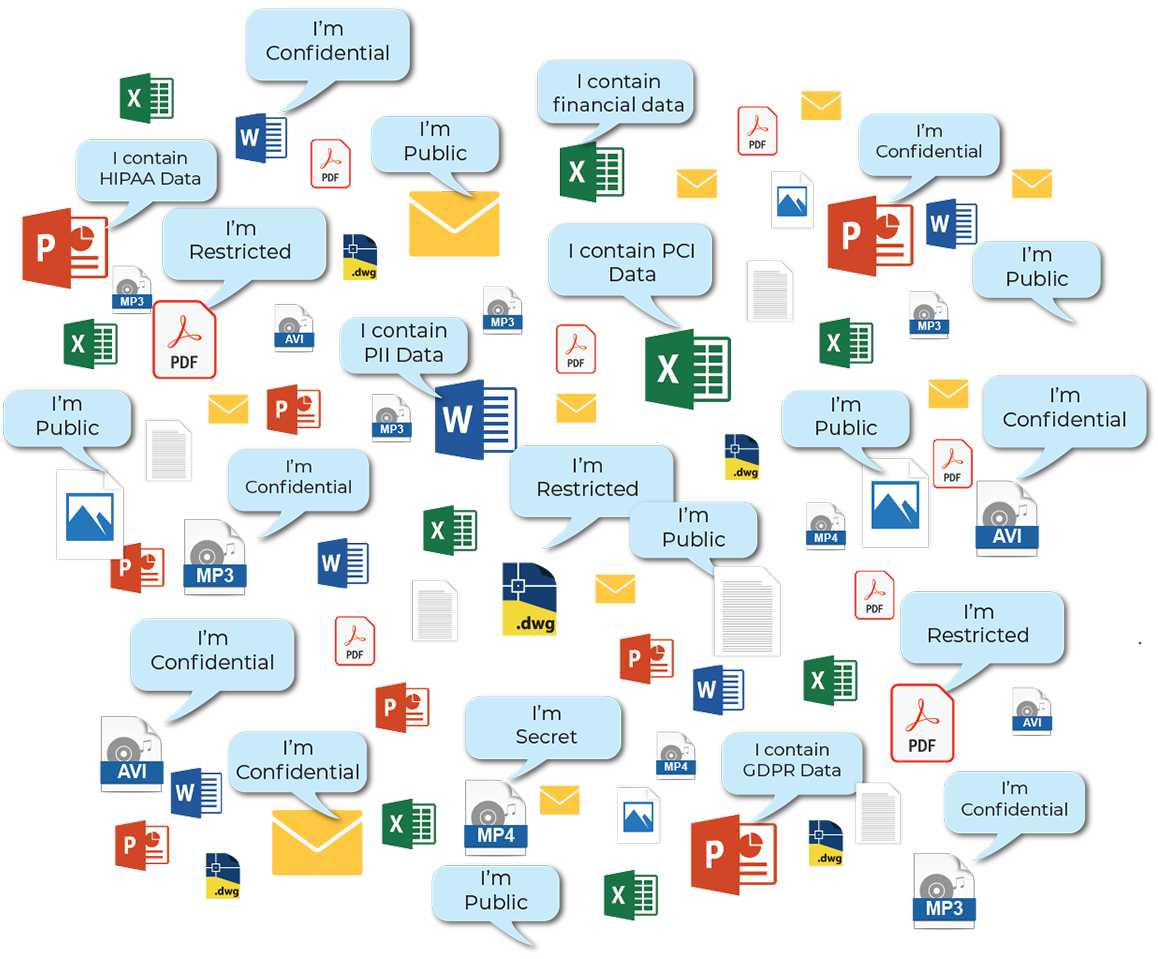
Types of Data Classification
Data classification can be performed based on content, context, or user selections:
- Content-based classification – inspects and interprets files looking for sensitive information. Defines the class of the file as per the perceived importance and confidentiality of the content.
- Context-based classification—involves classifying files based on meta data like the application that created the file (for example, CRM software), the person who created the document (such as Marketing department), or the location in which files were authored or modified (such as IT or legal department).
- User-based classification – involves classifying data files according to the best of intent judgement of an expert user. Individuals who work with documents can specify how sensitive they are – they can do so when they create the document, after a significant edit or review, or before releasing the document.
Which organizations need data classifications
- Organizations who are applied for any compliance
- Organizations stored users data
- Organizations communicate cross borders
- Organizations store financial records such as credit card and account information
- Organizations store PII data
- Organizations who care about their data